Tech & AI
Anthropic’s unusually
candid post-mortem
Anthropic published a post-mortem confirming the community’s
observations were accurate: three compounding bugs quietly degraded
Claude Code between March and April. (1) Reasoning effort was downgraded
from high to medium on March 4 to reduce
latency, making the model feel less intelligent for weeks; (2) a caching
bug introduced March 26 dropped thinking blocks every turn, making
Claude appear forgetful and burning usage limits; (3) a system-prompt
“≤25 words between tool calls” cap pushed April 16 caused a measured 3%
drop on coding benchmarks. Because the issues hit different segments on
different timelines, the combined effect looked like broad degradation.
All three fixed in v2.1.116 (April 20); usage limits reset for all
subscribers April 23. Anthropic committed to better testing and gradual
rollouts.
Sources: Anthropic
Engineering · HN · r/ClaudeAI
Cache
TTL cut from 1 hour to 5 minutes — not in the post-mortem
Separately, Anthropic reduced Claude Code’s prompt cache TTL from 1
hour to 5 minutes in early April, framing it as “reverting to default”
with no announcement. One tracked user saw cache busts jump from 39 to
199 per day and costs nearly triple — $6.28 → $15.54/day, ~+$277/month
projected. The change disproportionately hurts long agentic sessions
where any pause over 5 minutes forces a full expensive context rebuild.
No rollback has been announced.
Sources: XDA
Developers · r/ClaudeAI
Opus
4.7: mixed reactions, and the reasoning_effort dial
decoded
Multiple practitioners report Opus 4.7 (April 17) feels shallower and
less instruction-adherent than 4.6 despite more agentic posturing — one
tracking 6,852 sessions saw 80× more API requests and 170× more input
tokens for subjectively worse output. A common emerging pattern:
Codex/GPT-5.4 for research/architecture and Claude Code for automation,
with Claude-created PRs reviewed by Codex. A detailed 220-run benchmark
of Claude’s reasoning_effort parameter found the dial
mainly controls output token volume rather than input processing. Opus
4.7 uniquely scales thinking per turn (18% of tokens at low → 93% at
max); older models think on nearly every turn regardless. Sonnet 4.6 at
high delivers 5.1× more tokens per dollar than Opus 4.7 at
the same setting. Separately, Opus 4.6 still holds the top of the MRCR
v2 long-context retrieval benchmark. New tiered daily limits (“Claude
Design” research preview; “routine runs” quota) have also appeared
without documentation.
Sources: Jock’s
Thoughts · r/ClaudeAI
(weird) · r/ClaudeAI
(Codex) · George
Liu · r/ClaudeAI
(effort) · r/ClaudeAI
(MRCR) · r/ClaudeAI
(new tiers)
DeepSeek V4(-Pro) and GPT-5.5
DeepSeek released V4 (also V4-Pro on Hugging Face), claiming the best
open model for math and coding a year after shaking global tech markets.
OpenAI announced GPT-5.5, an incremental update in the GPT-5 family.
Sources: DeepSeek API
Docs · HN
(DeepSeek) · Al
Jazeera · OpenAI · HN
(GPT-5.5)
Karpathy’s CLAUDE.md at 81k
stars
A CLAUDE.md
file encoding four of Andrej Karpathy’s LLM coding guidelines has
accumulated 81k+ GitHub stars. The principles: think before coding,
simplicity first, surgical changes, goal-driven execution with
verifiable criteria. Works as Claude Code plugin, per-project CLAUDE.md,
or Cursor rules — reflecting growing interest in
configuration-as-behavior for agents.
Sources: GitHub
· r/ClaudeAI
AI
scientists execute but don’t reason — 25,000-run study
A paper (arXiv 2604.18805) evaluated LLM-based scientific agents
across 8 domains with 25,000+ runs. The findings: agents ignore gathered
evidence 68% of the time, update beliefs only when contradicted 26% of
the time, and never revise hypotheses in 71% of runs. The underlying
model explains 41% of performance variance; the agent framework explains
only 1.5%. Showing agents examples of successful scientific reasoning
didn’t help. Conclusion: current AI scientists execute the form of
science (hypothesise → experiment → result) without the substance
(evidence-driven belief revision). Training has to target reasoning
loops, not task completion.
Sources: arXiv via
AlphaXiv · r/MachineLearning
OCR: cheaper
and older models often beat flagships
An open-source
benchmark of 18 LLMs across 7,000+ OCR calls found that mini/older
models frequently match or beat flagship models on document extraction —
suggesting most teams are overpaying. Practical implication for AI-heavy
stacks: OCR/extraction is commodity work where cost-optimised routing
(Haiku, 4o-mini) can cut costs substantially without accuracy loss.
Sources: GitHub · r/MachineLearning
Ubuntu 26.04 LTS “Resolute
Raccoon”
26.04 ships with TPM-backed full-disk encryption, expanded
memory-safe components, improved app permission controls, and Livepatch
extended to Arm. Five years of maintenance; all nine official flavours
out simultaneously. A Zellic audit of rust-coreutils found 113 issues
and 43 CVEs (CVE-2026-35338 through 35381); eight TOCTOU bugs remain
unpatched in cp/mv/rm, so 26.04
continues shipping GNU coreutils for those three. Target for full
rust-coreutils: 26.10.
Sources: LWN · Ubuntu
release notes · HN · Lobsters
· Ubuntu
Discourse (coreutils) · Lobsters
(audit)
Why
openat() matters — Flatpak CVE-2026-34078
A deep dive into why path-based file APIs are fundamentally insecure:
a path string is not a reference to a file but a namespace lookup,
vulnerable to symlink attacks and TOCTOU races. The correct primitive is
openat() with file descriptors, which pins inodes in the
kernel. Flatpak recently patched CVE-2026-34078, where trusted-input
code was directly exposed to untrusted callers through paths — requiring
extensive refactoring to thread file descriptors throughout the
codebase.
Sources: Sebastian
Wick · Lobsters
Bitwarden
CLI npm package backdoored in Checkmarx campaign
@bitwarden/cli v2026.4.0 was backdoored via a
compromised GitHub Action in Bitwarden’s CI/CD pipeline, inserting
credential-harvesting code that targets GitHub tokens, AWS/Azure/GCP
credentials, npm tokens, and SSH keys — exfiltrating to
audit.checkmarx.cx. The payload also injects persistence
into .bashrc/.zshrc and propagates by stealing
npm tokens. Affected orgs: remove immediately, rotate all credentials,
audit CI/CD logs.
Sources: Socket · HN
MeshCore
splits over undisclosed AI use and a unilateral trademark
The mesh-networking project MeshCore has split after contributor Andy
Kirby was found to have used Claude to generate major firmware and app
components without disclosure, then filed for the MeshCore trademark
unilaterally. A community Discord poll found significant skepticism
about AI-generated firmware in critical infrastructure. The original
team (Scott, Liam Cottle, Recrof, FDLamotte, Oltaco) has moved to
meshcore.io/meshcore.gg; Kirby’s faction continues at meshcore.co.uk as
“MeshOS”. 38k+ global nodes and 100k+ app users in play.
Sources: MeshCore Blog ·
HN
Crawshaw’s
exe.dev; a For You feed from a home PC
David Crawshaw (Go net package) is launching exe.dev, rebuilding cloud from first
principles: direct CPU/memory provisioning (no VMs coupling them), local
NVMe with async replication, built-in TLS proxies, anycast networking —
addressing 10× IOPS penalties from remote storage and 10×-above-cost
egress. He ties the urgency to AI agents: more generated code means more
cloud usage, and current abstractions don’t hold up. In a similar vein,
a developer runs a popular Bluesky For You feed serving 72k daily users
from a home gaming PC (9950X3D, 96GB, 4TB NVMe) — ~$30/month vs $245
equivalent in cloud, 15–25 req/s at 37% CPU, two 400GB+ SQLite files
holding interaction data, Tailscale proxy via a small VPS to hide the
home IP. He estimates the current hardware could theoretically serve all
~1M active Bluesky users.
Sources: crawshaw.io · Lobsters
(Crawshaw) · AT Protocol
Blog · Lobsters
(feed)
Editors, assembly
desktops, Firefox config
A Linux desktop written entirely in x86_64
assembly — a tour of how thin the actual kernel interface really is.
Nev, a keyboard-driven
editor targeting both terminal and GUI. A comprehensive
guide to configuring Firefox — privacy, performance, workflow
customisations beyond the defaults.
Sources: Lobsters
(asm) · HN
(Nev) · Lobsters
(Firefox)
 Oil tankers and cargo ships lined up
in the Strait of Hormuz, seen from Khor Fakkan, UAE.
Oil tankers and cargo ships lined up
in the Strait of Hormuz, seen from Khor Fakkan, UAE. Acting Attorney General Todd Blanche
at a Justice Department press conference, April 21.
Acting Attorney General Todd Blanche
at a Justice Department press conference, April 21. Damage to residential buildings in
Odesa after overnight Russian drone strikes, April 24.
Damage to residential buildings in
Odesa after overnight Russian drone strikes, April 24.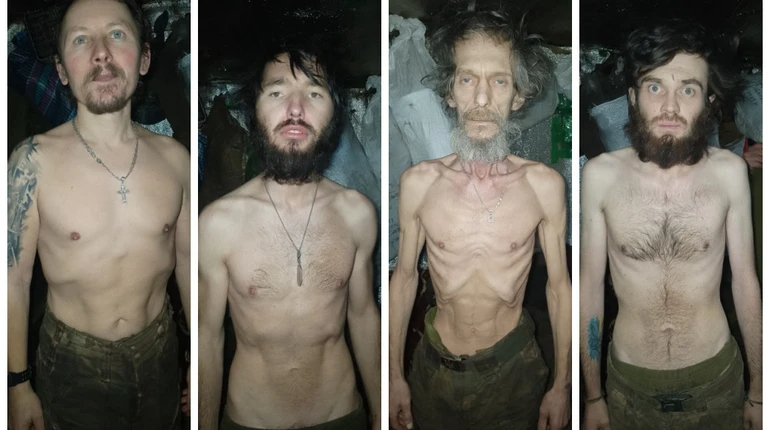 Soldiers of Ukraine’s 14th
Mechanised Brigade, whose commander was dismissed following
food-shortage reports near Kupiansk.
Soldiers of Ukraine’s 14th
Mechanised Brigade, whose commander was dismissed following
food-shortage reports near Kupiansk.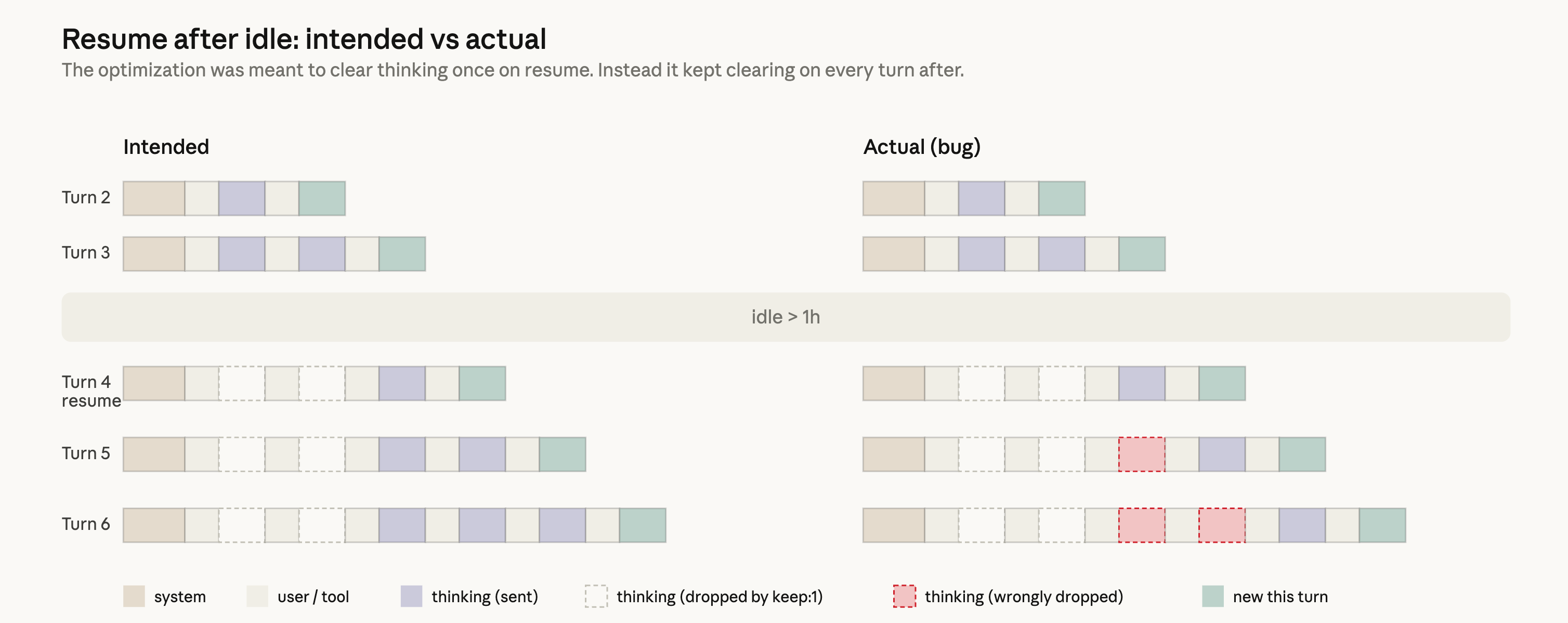 Anthropic’s post-mortem diagram
showing how reasoning blocks were dropped across multiple turns due to
the caching bug.
Anthropic’s post-mortem diagram
showing how reasoning blocks were dropped across multiple turns due to
the caching bug.